The Evolutionary Origins of Irreducible Complexity
To address a major Intelligent Design critique of evolutionary theory, Stephen Freeland discusses the progress mainstream science has made towards understanding the origin of genetic information.
One of the challenges for discussing evolution within evangelical Christian circles is that there is widespread confusion about how evolution actually works. In this installment, we examine evidence that proteins in irreducibly complex (IC) systems can form and refine new interactions through gradual mechanisms.
The Intelligent Design argument from Irreducible Complexity (IC)
Since this post, and those that will follow it, depend on an accurate representation of the argument for irreducible complexity (IC), I will take some time to clarify exactly how Michael Behe, the biochemist and Intelligent Design (ID) proponent who has most extensively developed the IC argument, uses the term. For Behe, the argument for IC is a critique of gradual evolutionary processes, of the kind that Darwin saw as necessary for his theory to hold. When Behe introduces and defines IC in his book Darwin’s Black Box, he has a key quote from Darwin on gradualism explicitly in view:
Darwin knew that his theory of gradual evolution by natural selection carried a heavy burden: “If it could be demonstrated that any complex organ existed which could not possibly have been formed by numerous, successive, slight modifications, my theory would absolutely break down.”
It is safe to say the most of the scientific skepticism about Darwinism in the past century has centered on this requirement… critics of Darwin have suspected that his criterion of failure had been met. But how can we be confident? What type of biological system could not be formed by “numerous, successive, slight modifications”?
Well, for starters, a system that is irreducibly complex. By irreducibly complex I mean a single system composed of several well-matched, interacting parts that contribute to the basic function, wherein the removal of any one of the parts causes the system to effectively cease functioning. An irreducibly complex system cannot be produced directly (that is, by continuously improving the initial function, which continues to work by the same mechanism) by slight, successive modifications of a precursor system, because any precursor to an irreducibly complex system that is missing a part is by definition nonfunctional. An irreducibly complex biological system, if there is such a thing, would be a powerful challenge to Darwinian evolution. (Darwin’s Black Box, p. 39)
The definition of an IC system is thus straightforward: it is a matched group of components, where all the components are necessary for the function of the system. The necessity of each component can be demonstrated by attempting to remove it – if the system no longer works if even one component is removed, it is by definition IC. Since an IC system requires all the components to be present for its function, it is not possible for the system, in its current state, to have been produced directly from a non-functional precursor. If one grants this premise, it leaves two options: that the IC system was derived indirectly, from a system that is not IC, or that the system was assembled by fiat and thus represents the actions of a designer. Behe’s criterion for distinguishing between these choices is based on evaluating the probabilities of these competing options:
Even if a system is irreducibly complex (and thus cannot have been produced directly), however, one can not definitively rule out the possibility of an indirect, circuitous route. As the complexity of an interacting system increases, though, the likelihood of such an indirect route drops precipitously. And as the number of unexplained, irreducibly complex biological systems increases, our confidence that Darwin’s criterion of failure has been met skyrockets toward the maximum that science allows. (Darwin’s Black Box, p. 40)
As we will examine in an upcoming post, Behe attempts to determine the precise limit of what evolutionary processes can (and cannot) achieve in a second book, The Edge of Evolution. For our present purposes, however, it is enough to note that the strength of the argument from IC depends on the perceived implausibility of the opposing explanation – that of an indirect evolutionary route that produces an IC system from a non-IC precursor system.
Building IC, one step at a time?
The presence of IC systems in biology as Behe has defined them is not contentious: there are many biological systems that cease to function when parts are removed. Indeed, the success of classical genetics in “dissecting” which genes are needed for certain functions largely rests on the ability to see some effect on function when a gene is removed from a system by mutation. What scientists dispute, however, is Behe’s claim that identifying IC systems is a hallmark of design. The evolutionary model for building IC is quite simple, and Behe has set it out as an option: an indirect route where non-essential parts are added to a system, and then over time the system comes to depend on those parts. We can diagram this model as follows:

The key to the model is that new parts can be added to a system, and that these parts are not essential when they are added. The resulting system is thus not IC, since it has parts that are not essential to its function, even if the new parts are advantageous in some way. If the new component is taken away at this stage, the system merely reverts to the precursor system. The second part of the model is that these intermediate, non-IC systems then may become IC if small changes make the new parts essential.
The addition of new, non-essential parts can be accomplished in several ways, such as a change in an existing protein that allows it to bind to a “precursor system”. More extreme would be the generation of a new protein that then adds to a precursor system as a non-essential component. Brand new genes, by definition, cannot be essential when they arise, since they arise in an organism that, up to that point, had no need of them. Looking to see if new genes then later become essential would be very good experimental support for the evolutionary model for how IC systems arise.
In practice, it takes a lot of scientific effort to tease out changes to an existing protein that allow it to become part of an intermediate system and then progress to an IC system, though we have examined one such example in a previous post. Looking for brand new genes, however, is much easier – and some recent work in several fruit fly species (Drosophila) has done just that.
The Young and the Restless
So, how to go about finding genes that are new? We have already discussed, in the context of duplicating an entire genome, how duplication of genes may lead to the two copies picking up new functions over time. While duplication may happen rarely at a whole-genome scale, small-scale duplication of small numbers of genes happens quite frequently as an error during cell division. At the time of the duplication, the two copies are the same, and therefore functionally equivalent. Over time, however, the two copies may become different and acquire distinct functions.
One way to look for genes that have arisen due to a recent duplication event is to compare the genomes of closely related species and look for genes that are present in one species but not another, or in a subset of related species. Duplicated genes will show up in a nested hierarchy, much like how pseudogenes appear in the same nested pattern, as we have discussed previously here.

The complete genome sequences for a number of fruit fly species are available, so researchers used this method of comparison to look for new genes that mostly arose “recently” (over the last 35 million years) within flies. Since the speciation times for the various fly species are known to a good approximation, the time of the various duplication events can be estimated as well.
Putting the argument for IC to the test
Using this method, researchers identified 195 recent, “young” genes that arose through duplication events. (Note: this finding, in and of itself, is problematic for the ID argument that significant amounts of new information cannot arise through evolutionary mechanisms). More problematic for the argument from IC, however, is that just less thanone third of these new genes are now essential for development in the species that carry them. This fraction is approximately the same for “old” genes – about one third are essential for development.
The implications are easily grasped: many new genes have arisen through duplication, and a sizeable fraction are now part of IC systems. When they arose, they could not have been essential, but now they are emphatically so. As such, they must have been added to previous systems, and become IC over time. Moreover, this effect is not a rare, one-off event, but rather has been repeated time and again in recent evolutionary history.
In the next post in this series, we’ll delve into some of the details about how these new genes arose, and what sort of functions they have.
Something old and something new; something borrowed and spliced into
In the last post in this series, we introduced a paper by Chen and colleagues that sought to identify new genes in various Drosophila (fruit fly) species. The youngest (i.e. the most recently evolved) gene they found is one specific to Drosophila melanogaster, the species of fruit fly beloved by geneticists as a model organism. The gene is named “p24-2” (not the most imaginative name, but it serves its purpose) and the gene it is duplicated from is called “Éclair”. The Éclair gene is found in a number of Drosophila species. A simplified “family tree” of three Drosophila species (D. melanogaster, D. simulans and D. erecta) is shown below. The duplication event that generated the p24-2 gene happened within the lineage leading to D. melanogaster, but after D. melanogaster and D. simulans separated as distinct species:

Since the entire genomes of these species are now sequenced and available online, it is possible to look at the chromosome region where the Éclair gene is found in all three. By looking at this region in D. melanogaster, we see that the brand-new p24-2 gene is almost right next door to its “parent” gene, Éclair. Below is a screen shot taken when looking at this region using a Drosophila “genome browser” that is freely available online. The red arrow indicates the Éclair gene, and we can see p24-2 is just one gene over, and seems to be nested within another gene called “Unc-115b”. The green arrows are pointing to two different “versions” of how p24-2 is made into an mRNA working copy. The Unc-115b gene (blue arrow) has five different mRNA versions. (One of the p24-2 mRNA versions has a lot of Unc-115b sequence that is not used when the p24-2 protein is made).
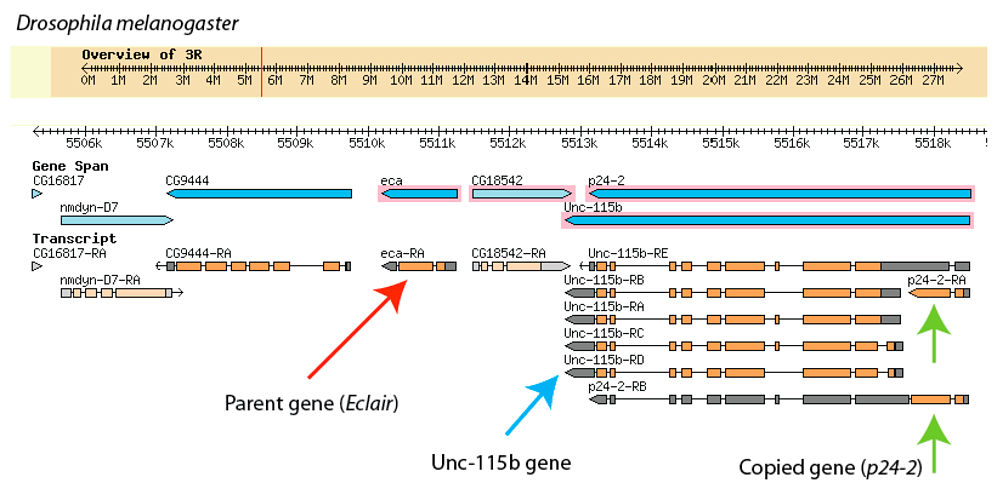
Click to enlarge
Finding a duplicated gene next door to the sequence it is copied from is pretty common in genomes – when chromosomes are copied or recombined during cell division, side-by-side copies of parts of chromosomes show up every now and then. It’s also not surprising to see a new gene cobbled together with another gene. In this case, Unc-115b and p24-2 are overlapping but separate functional entities: they each have their own protein sequences, but each includes the code of the other as a sequence that does not actually translate into protein. The details of how this “cobbling” happens aren’t important for this discussion, other than to note that the mechanisms are known and not rare. In the chart above, then, the orange sections indicate the active parts of the transcribed sequence, while the gray are sections that are included in the RNA molecule, but do not get used directly to code for the new protein.
When we look at this same chromosome region in D. simulans and D. erecta, however, p24-2 is missing. Éclair and Unc-115b are there, but p24-2 is not, since it arose after D. melanogaster separated from its common ancestors with the other species. (Note: this entire region is a mirror image in D. simulans and D. erecta when compared to D. melanogaster due to a large scale chromosome inversion that covers this whole area. So, while it looks “backwards” compared to the image above, that is not surprising, it’s expected):

Click to enlarge
So, with the p24-2 gene in D. melanogaster, we have a bona-fide, recent gene duplication event. This gene is brand new, evolutionarily speaking (less than 3 million years old, given the calculated speciation times of D. melanogasterand D. simulans). Not only is it brand new, it is also essential for survival in D. melanogaster: if you remove it, the fly dies. Obviously, since every other Drosophila species lacks p24-2, this gene is not essential for survival for any other species. It’s new, and now it’s necessary.
Do new, essential genes refute the Intelligent Design (ID) argument from Irreducible Complexity (IC)?
So far, nothing we have discussed explicitly threatens the ID argument from IC, though it does threaten the ID argument that new information cannot arise through evolution, a topic we have discussed in detail before. Michael Behe, the main ID proponent of the argument from IC, has commented on this research by Chen and colleagues (thanks to commenter “Bilbo” for pointing this out). Behe’s rejoinder was to a blog post by biologist and atheist blogger Jerry Coyne, who used the paper by Chen and colleagues to attack Behe’s ideas. Since Behe’s reply deals with his understanding of how gene duplication relates to his argument from IC, I will quote it here at length:
I have never stated, nor do I think, that gene duplication and diversification cannot happen by Darwinian mechanisms, or that “they play almost no role at all” in the unfolding of life. (As a matter of fact, I discussed several examples of that in my 2007 book The Edge of Evolution. That would be silly — why would anyone with knowledge of basic biochemical mechanisms deny that, say, the two gamma-globin coding regions on human chromosome 11 resulted from the duplication of a single gamma-globin gene and then the alteration of a single codon? What I don’t think can happen is that duplication/ divergence by Darwinian mechanisms can build new, complex interactive molecular machines or pathways. Assuming (since he is in fact critiquing them) Professor Coyne has been attentive to my arguments, one background assumption that he may have left unexpressed is that he thinks the newer duplicated genes discovered by Professor Long’s excellent work represent such complex entities, or parts of them.
There is no reason to think so. A gene can duplicate and diversify without building a new machine or network, or even changing function much. The above example of the two gamma-globin genes shows that duplication does not necessarily result in change in function. The examples of delta- and epsilon-globin, which, like gamma-globin, presumably also resulted from the duplication of an ancestral beta-like globin gene, show that sequence can diversify further, but function remain very similar. Even myoglobin, which shares rather little sequence homology with the other globins, has not diverged much in biochemical function.
In his recent work Professor Long discovered that many of the new genes were essential for the viability of the organism — without the gene product, the fruitflies would die before maturity. Perhaps Professor Coyne thinks that that means the genes necessarily are parts of complex systems, or at least do something fundamentally new. Again, however, there is no reason to think so. The notion of “essential” genes is at best ambiguous. We know of examples of proteins that surely appear necessary, but whose genes are dispensable. The classic example is myoglobin. It is also easy to conceive of a simple route to an “essential” duplicate gene that does little new. Suppose, for example, that some gene was duplicated. Although the duplication caused the organism to express more of the protein than was optimum, subsequent mutations in the promoter or protein sequence of one or both of the copies decreased the total activity of the protein to pre-duplication levels. Now, however, if one of the copies is deleted, there is not enough residual protein activity for the organism to survive. The new copy is now “essential”, although it does nothing that the original did not do.
The main points of Behe’s reply can be summarized as follows:
- Gene duplications and subsequent changes to the copies (diversification) can and do happen, but the results are nothing really “new”— no new molecular machines or pathways (nor parts of such pathways), nor much in the way of new functions.
- Duplicated genes can become essential simply by “sharing” the original function, and then reducing their share to a minimum, perhaps through the amount of protein that each copy makes. Again, this is not anything really new, since the copy doesn’t do anything that the original didn’t do already. So, the finding that some gene copies are essential genes is not a threat to the IC argument.
Note that Behe’s reply makes predictions that can be tested with further research. These predictions might be summarized in this way:
- If IC is correct, duplicated genes will not be part of new, complex molecular pathways or machines.
- If IC is correct, duplicated genes that are both essential should “share” the original function.
Testing IC with new research
Behe’s reply to the Chen paper is of course hypothetical and speculative – as demonstrated by his own comment that “there is no reason to think” that the duplicated genes are components of new complex pathways or systems. Accordingly, the validity of Behe’s reply depends on its ability to hold up over time as more work is done. Of note, the functions of p24-2 and its parent gene Éclair have been studied intensively since 2010. These studies, as we shall see in the next post in this series, shed quite a bit of light on these questions.
In the previous section we introduced the p24-2 gene, a brand-new gene identified in a large survey that compared several fruit fly (Drosophila) genomes to each other. The p24-2 gene stuck out like a sore thumb in this survey because it is present in only one fly species (Drosophila melanogaster). This gene arose from a duplication of a nearby gene (the Éclair gene) after D. melanogaster parted ways with other fly species within the last 3 million years. Pairs of recently duplicated genes and their “parent” genes are interesting to biologists studying how new gene functions arise—as well as an excellent opportunity to test the Intelligent Design (ID) argument from Irreducible Complexity (IC), as we discussed in the last section.
Éclair and p24-2 have distinct essential functions
The Éclair and p24-2 genes are part of a larger gene family in flies called p24 proteins. There are nine p24 protein genes in most Drosophila species, but the recent addition of p24-2 in D. melanogaster brings the total for this species to ten. The p24 protein family is a group of proteins that is widespread among diverse forms of life, such as plants, animals, and fungi. The various p24 proteins act as carriers for other proteins as they shuttle them from where they are made in the cell (the endoplasmic reticulum, or ER) to the Golgi apparatus(another location in the cell where proteins are modified and sorted). The p24 proteins do their jobs by binding their “cargo” proteins and loading them into small membrane spheres called vesicles that do the physical shuttling back and forth to different compartments within the cell.
Since p24-2 is a recent duplication of Éclair, the two genes are very similar at the structural level. Indeed, their amino acid sequences are nearly identical, as you might expect:

Of the 206 amino acids in each protein, only five differ between the two genes. (The figure above shows the amino acids for both genes using a single-letter code, and the differences are highlighted). Though these sequences are highly similar, already we see hints that the two genes are not equivalents. In fact, the difference between these two genes is already a little greater than the average difference we see between human and chimpanzee genes, and the separation of these two genes occurred much more recently than the human-chimpanzee split. Also, most of the differences are clustered at the one end of the protein, suggesting that a protein-protein binding domain has been altered. (See here for a description of binding regions that similarly latch onto sections of DNA)
Further work has confirmed the hypothesis that p24-2 and Éclair are not functionally equivalent genes. Several lines of evidence support this conclusion:
- Different defects are seen when the two genes are removed. While removing either gene usually results in the death of the fly, some rare flies do survive to adulthood. The survivors, however, have different defects: the loss of the Éclair gene results in female flies that cannot lay eggs, but loss of the p24-2 gene has no effect on egg laying at all.
- Éclair and p24-2 are not always found in the same cell types during development. For example, p24-2 protein is not found in the ovaries of adult females, whereas Éclair protein is very abundant in this tissue. This difference likely explains why removing Éclair is so detrimental to laying eggs, but removing p24-2 is of no consequence at all for egg laying.
- Éclair seems to share some functions with other p24 proteins that are less closely related to it than p24-2 is. For example, the “Basier” gene is found in all the same tissues in which Éclair is found. If a fly lacks Éclair, then it must have Basier (the flies all die if Basier is also removed). Similarly, when a fly lacks Basier, no loss of Éclair can be tolerated. These two genes work together and share their essential functions.
- One target “cargo” of Éclair has been identified – an important signaling protein called Wingless. The Wingless protein needs to be exported out of the cell in order to do its job, and without functional Éclair present, Wingless cannot make it from the ER to the Golgi, which it needs to do in order to be exported. The p24-2 protein, however, is completely dispensable for exporting Wingless. Thus p24-2 and Éclair are involved in transporting different cargo proteins. Éclair shares the function of exporting Wingless with another p24 family member (called Emp24), but notwith its closer relative, p24-2.
In summary, while p24-2 and Éclair are both essential genes, they are involved with different essential functions. They transport different cargo proteins (in some cases in different tissues), and they show different defects when they are removed. While there is some sharing of function among p24 family members, Éclair shares with proteinsother than p24-2.
Implications for the ID argument from IC
In our previous section we discussed ID proponent Michael Behe’s response to the 2010 paper that identified the new genes in Drosophila. In his response, Behe explained why he felt that paper was not a threat to the ID argument from IC:
I have never stated, nor do I think, that gene duplication and diversification cannot happen by Darwinian mechanisms, or that “they play almost no role at all” in the unfolding of life… What I don’t think can happen is that duplication/ divergence by Darwinian mechanisms can build new, complex interactive molecular machines or pathways…
It is also easy to conceive of a simple route to an “essential” duplicate gene that does little new. Suppose, for example, that some gene was duplicated. Although the duplication caused the organism to express more of the protein than was optimum, subsequent mutations in the promoter or protein sequence of one or both of the copies decreased the total activity of the protein to pre-duplication levels. Now, however, if one of the copies is deleted, there is not enough residual protein activity for the organism to survive. The new copy is now “essential”, although it does nothing that the original did not do.
We also discussed how Behe’s thoughts could be expressed as testable hypotheses:
If IC is correct, duplicated genes will not be part of new, complex molecular pathways or machines.
If IC is correct, duplicated genes that are both essential should “share” the original function.
As we can now see, these hypotheses have not been supported through additional work on Éclair and p24-2. We now do have good reason to think that p24-2 is involved in its own complex molecular pathway, and that it is not merely sharing an essential function with its parent gene Éclair. While we do not yet have all the details of how p24-2 and Éclair work, we already know that p24-2 performs its essential role without merely propping up the function of its parent gene. We also know that it carries a different cargo that Éclair is carries. It appears to have developed a new protein-protein interaction that allows it to carry something else. This role could not have been essential when it first arose, but it is essential now.
In summary, the evidence strongly suggests that the essential function of the p24-2 gene qualifies as IC in the ID sense, and that this IC function arose through an evolutionary process. Even if ID supporters quibble over the precise details of the Éclair/p24-2 story, the more important issue is one that is hopefully now abundantly clear: evolutionary processes can add new components to already complex molecular systems; such additions cannot be essential when they are added; and additions can later become essential as the system comes to depend on them as other changes accumulate. Given this, the ID argument from IC is susceptible to false positives: IC systems are not reliable indicators of “design” in the ID sense, since evolutionary mechanisms can produce them. In the next section, we will examine other examples of IC systems and the evidence for their evolutionary origins.
Can IC systems add new components?
In the last section, we discussed the evidence that a new gene (p24-2) in one species of fruit fly had picked up functions distinct from the “parent” gene (Éclair) from which it was copied. For new proteins to pick up new functions, new interactions between proteins need to form – new binding sites that allow proteins to come together to do specific tasks. One line of evidence that p24-2 had acquired a new protein-protein interaction was the observation that a series of amino acids concentrated in one region of p24-2 were markedly different than those in Éclair. This observation suggests the possibility that this region allows p24-2 to participate in a protein-protein binding interaction that Éclair cannot, though this hypothesis has not yet been tested.

The ability of an IC system to develop new protein-protein interactions is a subject that Michael Behe discusses at some length in The Edge of Evolution. Specifically, Behe states:
The conclusion from Chapter 7 – that the development of two new intracellular protein-protein binding sites at the same time is beyond Darwinian reach – leaves open, at least as a formal possibility, that some multiprotein structures (at least ones that aren’t irreducibly complex in the sense defined in Darwin’s Black Box) might be built by adding one protein at a time, each of which is an improvement. But there are strong grounds to consider even that biologically unreasonable. First, the formation of even one helpful intracellular protein-protein binding site may be unobtainable by random mutation. The work with malaria and HIV, which showed the development of no such features, puts a floor under the difficulty of the problem, but doesn’t set a ceiling. Maybe my conservative estimate of the problem of getting even a single useful binding site is much too low. What we know from the best evolutionary data available is compatible with not even a single kind of specific, beneficial, cellular protein-protein interaction evolving in a Darwinian fashion in the history of life. (p. 157)
So for Behe, the formal possibility remains open that non-IC systems might be able to add parts one protein at a time, though he considers even this possibility as unlikely. Note, too, that IC systems are excluded from this possibility altogether.
(Note: I realize that Behe has already been shown to have been mistaken about HIV not forming any new protein-protein interactions, though this is usually blunted by appealing to the very large mutation rate that HIV has. While this is a genuinely serious critique of Behe’s argument, I will not re-hash this example here).
The challenge of time
Studying processes that span millions of years or more has unique challenges. Take continental drift, for example. When continental drift was a new idea, it did make sense of a wide array of observational data: the suggestively complementary shapes of Africa and South America, the rock and fossil formations on their coasts that matched the right locations on the other continent, and so on. Later work discovered the mid-Atlantic ridge, and other lines of evidence that supported the idea that all modern continents were once a supercontinent called Pangaea. Nowadays we can measure the tiny, incremental movement of continents with great precision. These measurements provide experimental data that neatly dovetails with the historical and observational lines of evidence. Together, they paint a consistent picture of how the continents got to be where they are today.
A critic of continental drift, however, might argue that researchers have not connected the observational evidence with the experimental evidence: after all, the amount of continental movement we observe is small, and the observational evidence is circumstantial. Also, the amount of change suggested by the observational data is huge, but we observe only tiny changes in the present. How can we be sure that we have an adequate explanation for the mechanism(s) of continental drift?
While this is something of a hypothetical example (since critics of continental drift are relatively few and far between) the issues are the same for studying how protein-protein interactions arise over evolutionary history. As with continental drift, evolutionary biology is supported by a wide array of data (comparative genomics, for example) that suggests robust change over millions of years. Likewise also, studies we are capable of running in the present have an extremely short duration (perhaps at best decades) compared to the long-term process we are studying. Not surprisingly, we expect the changes we observe in the present to be modest. Despite these issues, however, certain elegant experiments do manage to document changes in great detail. Of particular relevance for assessing Behe’s argument is some recent work that “caught” the development of a new protein-protein binding site in the act, as it were.
Consider the phage

Source: NY Times
The study of interest was done in the laboratory of Richard Lenski, the same laboratory running the Long Term Evolution Experiment on E. coli that we have discussed before. In this instance, the object of the experiment was a virus that infects E. coli and breaks it open as part of its replication cycle (with lethal consequences for the bacterial host). Since the virus is a “bacteria eater” it goes by the title “bacteriophage”, in this case bacteriophage lambda, or alternatively “λ phage”. λ phage starts the process of infection by using one of its proteins to attach to a protein on the bacterial surface, and the researchers were interested to know how hard it would be for the phage to develop the ability to attach to a new protein and use that new protein to infect its host.
Normal λ phage uses its protein called “J” to bind to a host protein called LamB. The researchers used a genetic trick to almost entirely remove LamB from a population of E. coli hosts, making them impervious to the presence of λ phage. To keep a tiny amount of λ phage alive in the bacterial culture, however, the researchers rigged it so that every so often a susceptible host with LamB would be produced. With things balanced in this way, most E. coli in the culture were unable to be infected, but a tiny minority of hosts kept a small population of λ phage going alongside them. If λ phage could figure out a way to use another host protein to infect these resistant bacteria, it would have access to a large number of hosts it could not previously access.
What the researchers found was that λ phage was able to switch over to use a different host protein, one called OmpF. OmpF and LamB are similar in overall shape, but not that similar at the sequence level. Since the switch happened over a matter of weeks in a controlled environment, the research team was able to document the mutations that led to the switch. The study produced some interesting findings:
- The change to using OmpF instead of LamB required at least four mutation events in protein J. These changes clustered together in one protein region.
- The probability of these four mutation events happening simultaneously is pretty much zero, yet the λ phagemanaged to “find” these mutations over and over again without much trouble, with the mutations happening sequentially, not simultaneously.
- There were numerous mutational paths that the λ phage took to arrive at the new function of protein J binding to OmpF.
- The mutations did not remove the ability of protein J to bind LamB, but improved its binding. This was important, since at no point could the λ phage lose the ability to bind LamB if it was to survive.
- The λ phage strains that gained the ability to bind OmpF can still use LamB to infect cells that have it. This means that the new protein-protein interaction between J and OmpF is a gain of a new function without any loss of the prior function.
Taken together, these results suggest that the ability to form new protein-protein interactions may be much easier than Behe has estimated. In the next installment in this series, we’ll continue to examine the implications of this study for Behe’s argument, and evaluate Behe’s response to this important work.
In the last section, we introduced an elegant experiment on virus evolution done by the Lenski group, and suggested that, despite Behe’s claim to the contrary, this work poses some significant challenges to Behe’s arguments. We now turn to those arguments in detail.
Has Behe found the Edge of evolution?
Behe lays out his detailed case for what evolution can and cannot do in his 2007 book The Edge of Evolution. In a chapter called “The two binding-sites rule,” Behe lays out his argument for defining the “edge”– the limit of what random mutation and selection can do to create new protein-protein binding sites:
So one way to get a new binding site would be to change just five or six amino acids in a coherent patch in the right way. This very rough estimation fits nicely with studies that have been done on protein structure. Five or six amino acids might not sound like very much at first, since proteins are often made of hundreds of amino acids. But five or six amino acid substitutions means that reaching the goal requires five or six coherent mutational steps – just to get two proteins to bind to each other. As we saw in the last chapter, even one missing step makes the job much tougher for Darwin than when steps are continuous. If multiple steps are missing, the job becomes exponentially more difficult. (p. 134)
Then after an aside where Behe considers the possibility that some of the mutations might be neutral (and thus not be required to happen simultaneously), he settles on an estimate of three or four simultaneous mutations to effect a new protein-protein binding site:
So let’s suppose that of the five or six changes that have to happen to a protein to make a new binding site, a third of them are neutral. They could occur before the other key mutations, as a separate step, without harm. Although finding the right neutral changes would itself be an improbable step, we’ll again err on the conservative side and discount the average number of neutral mutations from the average number of total necessary changes. That leaves three or four amino acid changes that might cause trouble if they occur singly. For the Darwinian step in question, they must occur together. Three or four simultaneous mutations is like skipping two or three steps on an evolutionary staircase. (p. 134)
Note well: Behe’s model is based on an assumption that new protein-protein binding sites require multiple, simultaneous amino acid substitutions. Behe continues the argument:
Although two or three missing steps doesn’t sound like much, that’s one or two more Darwinian jumps than were required to get chloroquine resistance in malaria. In chapter 3 I dubbed that level a “CCC”, a “chloroquine complexity cluster,” and showed that its odds were 1 in 1020 births… Now suppose that, in order to acquire some new, useful property, not just one but two new protein-binding sites had to develop. A CCC requires, on average, 1020, a hundred billion billion, organisms – more than the number of mammals that has ever existed on earth. So if other things were equal, the likelihood of getting two new binding sites would be what we called in Chapter 3 a “double CCC”- the square of a CCC, or one in ten to the fortieth power. Since that’s more cells than likely have ever existed on earth, such an event would not be expected to have happened by Darwinian processes in the history of the world. (pp. 134-135)
Again, note well: in his estimation of the probability of generating two new protein-protein binding sites that perform a specific function, Behe calculates it as the square of the probability of getting one. This means that Behe is assuming that the two probabilities are independent, and thus all the non-neutral mutations (for both new binding sites) occur simultaneously. From this calculation, he concludes:
Admittedly, statistics are all about averages, so some freak event like this might happen – it’s not ruled out by force of logic. But it is not biologically reasonable to expect it, or less likely events that occurred in the common descent of life on earth. In short, complexes of just three or more different proteins are beyond the edge of evolution… And the great majority of proteins in the cell work in complexes of six or more. Far beyond that edge. (p. 135)
Indeed, mutations that simultaneously changed six to eight amino acids to instantaneously bring about two new protein-protein binding sites would be a freak event. (Note: I am aware that the precise numbers Behe uses have been criticized, but I’ll assume them for the sake of argument). The real question, though, is whether new protein-protein binding sites require simultaneous mutations. If they do, then Behe might have a case. But if new binding sites can arise one amino acid substitution at a time, however, then Behe’s case is based on a flawed assumption. In this case, protein complexes could add new binding partners one protein at a time, and build up systems of numerous proteins gradually, in a step-wise manner. Moreover, if one new binding site can arise gradually, then it is reasonable to expect that multiple binding sites could also arise without requiring simultaneous mutations.
Adding new protein binding partners, one amino acid substitution at a time
This is where the experiment done by the Lenski group on λ phage evolution (that we introduced in the last post in this series) becomes a key test of Behe’s hypothesis that simultaneous mutations are required for new protein-protein binding sites. (Readers may wish to refresh their memory of this experiment before continuing). The key points are as follows:
- For protein J of λ phage to bind to the new partner, OmpF, at least four amino acid substitutions were required before the new binding ability arose. Only with the fourth substitution did the new binding take place.
- The probability of these four mutation events happening simultaneously is pretty much zero (approximately one in a thousand trillion trillion). This is well beyond the probability “edge” that Behe claims.
- In repeated experiments, the λ phage managed to “find” these mutations over and over again without much trouble.
- Subsequent analysis showed that the amino acid substitutions happened sequentially, not simultaneously.
Over the edge, with ease
As we have seen, Behe’s argument for defining the edge of what evolution can do is based on his assumption that multiple mutations producing certain amino acid substitutions must occur at the same time in order for new protein-protein binding sites to arise. What the Lenski experiments on λ phage demonstrate, however, is that new protein–protein binding sites can arise just fine by accumulating random amino acid substitutions one at a time, even if numerous mutations are needed to achieve the new binding properties. Moreover, they can arise just fine by many different routes, and not always with the exact same mutations present, and this result can be repeated in the lab over and over.
In short, the fundamental assumption of Behe’s model has not stood up to experimental scrutiny. If new protein-protein binding sites can (and do) arise in this way, Behe’s assertion that several mutations must occur at the same time falls apart, and with it his proposed “edge” of what evolution can do. Behe has drawn a line in the sand, but we’ve watched evolution stroll right over it as if it wasn’t there—one amino acid substitution at a time.
“So nat’ralists observe, a flea
Hath smaller fleas that on him prey,
And these have smaller fleas that bite ’em,
And so proceed ad infinitum.”
–Jonathan Swift
Has λ phage evolved a new IC system?
In the last section, we discussed the results of an experiment done by the Lenski group on λ phage evolution, and some of its implications for the argument from irreducible complexity (IC). We now turn our attention to the question of whether the new function observed to arise in this experiment constitutes a new IC system. Recall that in Darwin’s Black Box, Behe (a) introduces IC systems as something beyond the abilities of evolution to produce gradually, and (b) defines them as follows:
What type of biological system could not be formed by “numerous, successive, slight modifications”? Well, for starters, a system that is irreducibly complex. By irreducibly complex I mean a single system composed of several well-matched, interacting parts that contribute to the basic function, wherein the removal of any one of the parts causes the system to effectively cease functioning. (pg. 39)
For λ phage, the original system of protein J binding to LamB on the outer membrane of E. coli is one interaction out of several that are essential for its replication. These interactions are a single system that requires well-matched parts (for precise protein binding) that contribute to the basic function (replication of the phage). If either LamB or protein J are disrupted, the system ceases to function (the phage loses the ability to replicate). By Behe’s definition, this is an IC system.
The new system is similarly IC: protein J now binds to OmpF on the outer membrane, and this interaction requires well-matched, interacting parts. The other steps in the phage replication cycle are the same, and use the interactions present in the previous IC system. As before, removal of either protein J or its binding partner (now OmpF) causes the system to cease functioning (since at this point in the experiment LamB is already missing). The new system is also IC according to Behe’s criteria.
But here’s the rub: in this experiment, the researchers observed the new IC system form step by step through “numerous, successive, slight modifications” to the previous IC system. At no point did those modifications remove the function of the original system, but in fact improved it (the modified protein J binds to its original partner, LamB, even more effectively than before).
Has λ phage jumped the Edge?
Beyond its troubling ability to generate new IC complexes by modifying old ones, λ phage evolution, as we have seen, is similarly troubling for the probability argument Behe lays out in his book Edge of Evolution. The key section (that we have discussed previously) is as follows:
Although two or three missing steps doesn’t sound like much, that’s one or two more Darwinian jumps than were required to get chloroquine resistance in malaria. In chapter 3 I dubbed that level a “CCC”, a “chloroquine complexity cluster,” and showed that its odds were 1 in 1020 births… Now suppose that, in order to acquire some new, useful property, not just one but two new protein-binding sites had to develop. A CCC requires, on average, 1020, a hundred billion billion, organisms – more than the number of mammals that has ever existed on earth. So if other things were equal, the likelihood of getting two new binding sites would be what we called in Chapter 3 a “double CCC”- the square of a CCC, or one in ten to the fortieth power. Since that’s more cells than likely have ever existed on earth, such an event would not be expected to have happened by Darwinian processes in the history of the world.
Admittedly, statistics are all about averages, so some freak event like this might happen – it’s not ruled out by force of logic. But it is not biologically reasonable to expect it, or less likely events that occurred in the common descent of life on earth. In short, complexes of just three or more different proteins are beyond the edge of evolution… And the great majority of proteins in the cell work in complexes of six or more. Far beyond that edge. (pp. 134-135)
The key point being that mutations, in Behe’s model, are simultaneous mutations, not sequential ones.
Drawing the argument together from both Darwin’s Black Box and Edge of Evolution, we can summarize Behe’s argument with three statements:
- Evolution of protein-protein binding sites cannot proceed by multiple, simultaneous mutations because the probability of such events is too rare to be expected to happen during the history of life on earth.
- Evolution must proceed only by multiple, simultaneous mutations to create new protein-protein binding sites. Gradual modifications to produce new IC systems are not possible.
- Thus when we observe complexes with more than three protein-protein binding partners, we can infer that they were not produced by evolution.
The difficulty with this argument is that Behe has not established the second point, but merely asserted it: that evolution must proceed only by multiple, simultaneous mutations to create new protein-protein binding sites. Indeed, Darwin’s original prediction was that “new” systems would not really be “new” at all, but rather gradually modified from previously existing systems through accumulation of small changes. If protein-protein complexes (including IC ones) can be built up over time by gradual addition of new components, then Behe cannot claim statement 3, even if statement 1 remains uncontroversial.
The evidence we have seen from λ phage is doubly problematic for the argument from IC: not only has a new IC system been formed, but its stepwise formation, one amino acid substitution at a time, was repeatedly documented in detail.
λ phage, that tiniest of fleas, has inflicted quite a bite on the argument from IC.
What about other lines of evidence?
As compelling as the evidence from this detailed experiment is, it is not the only evidence that points to the conclusion that new protein-protein interactions, functions and systems can arise gradually. Other lines of evidence we have examined include:
The similarities between whole genomes that speak to gradual change at the nucleotide and amino acid levels over large evolutionary times: the sequence differences between the human and chimpanzee genomes, for example, are tiny. Yet despite these minute differences at the genomic level, we (obviously) exhibit many traits that chimpanzees do not. The obvious conclusion is that the accumulation of small genetic changes to complex systems can have dramatic effects on function.
The gradual emergence of anaerobic citrate metabolism in an experimental population of E. coli bacteria: As we saw when we examined this system, a new, advantageous trait arose piecemeal, eventually cobbling together a new function from mutations that occurred tens of thousands of generations apart in some cases. This evidence further undermines the contention that evolution requires simultaneous mutations.
The recently duplicated p24-2 gene in Drosophila: Whatever p24-2 and Éclair are doing, exactly, there is good evidence to suggest they are not merely duplicates of each other, but have distinct functions. It’s highly likely that p24-2 has developed new protein-protein interactions of some kind (unless we wish to posit that p24-2 does its job without interacting with any other proteins at all, which is highly unlikely). We do not yet know if these genes are involved in IC systems, though the fact that they are required for survival suggests that they have important roles. Interestingly, Behe’s reply to my argument in part discusses how existing IC systems might add components:
Now what we have here is an already-intact transport system. At best, the amino acid changes in p24-2 would be analogous to re-arranging the magnets at the end of the oval-shaped object, so that it could transport a different object than before. But that is just taking advantage of an already-existing IC system; it is not a new one.
I would argue that observing new components adding themselves to already complex systems, and then becoming essential, is just the type of gradualism that evolutionary theory predicts. Behe continues:
A final point is that there are five specific amino acid differences between Eclair and p24-2. Professor Venema seems not to comprehend that they may not have arisen by random mutation. Once one gets beyond one or two random mutations, one can’t assume that multiple further mutations arose by chance. In other words, as far as anyone knows, those five point mutations may have required guidance or design in their appearance.
But as we have seen, the (repeated) accumulation of five or more amino acid substitutions in protein J of λ phage was no problem at all, despite the astronomical odds of all the needed mutations happening at once (note too that Behe’s argument depends on simultaneous mutations, as we have seen). There is no need to assume that the differences between p24-2 and Éclair arose by chance, but rather cite the evidence that multiple amino acid changes have been observed to accumulate over time in other systems. While we cannot recreate the last 3 million years of Drosophila evolution, it seems strained to argue that this time span is insufficient to generate the same amount of change that we observe in the laboratory in a matter of weeks in other, more tractable systems.
About the author

Dennis Venema
Related resources
If you enjoyed this article, we recommend you check out the following resources:


Language of God
Sy Garte | Life’s Deeper Logic


Language of God

Language of God

Language of God